Mysql 강의 04. mysql update 문의 모든것
기본 구문
1 | UPDATE 테이블명 SET 필드명 = "바꿀 값" WHERE 필드명= "조건 값" |
특정 column 값을 increase 시키기
1 | UPDATE mytable |
2. mysql insert 문의 모든것
AUTO_INCREMENT의 시작값 변경해 주기
데이터를 정리하기 위해 시작 하는 primary 키의 AUTO_INCREMENT 값을 변경해 주어야 할 경우가 있다.
다음 명령어를 통해 원하는 값부터 다시 AUTO_INCREMENT가 시작되도록 할 수 있다.
1 | ALTER TABLE [테이블명] AUTO_INCREMENT=[시작할려는 순서] |
ON DUPLICATE KEY를 이용한 중복키 관리
여러개의 데이터를 한번에 입력할 때 기존에 있던 데이터는 키값은 유지하고 내용만 변경해야 할 경우가 있다.
이 경우는 on duplicate key 를 활용하면 기존에 있던 데이터를 유지하면서 변경된 내용만 업데이트를 시켜줄 수 있다.
example1
2
3
4
5
6
7
8
9
10
11INSERT INTO mytable (id, a, b, c)
VALUES (1, 'a1', 'b1', 'c1'),
(2, 'a2', 'b2', 'c2'),
(3, 'a3', 'b3', 'c3'),
(4, 'a4', 'b4', 'c4'),
(5, 'a5', 'b5', 'c5'),
(6, 'a6', 'b6', 'c6')
ON DUPLICATE KEY UPDATE id=VALUES(id),
a=VALUES(a),
b=VALUES(b),
c=VALUES(c);
INSERT IGNOE를 이용한 중복키 단순히 무시하기
여러개의 데이터를 한번에 입력할 때 기존에 있던 정보는 아예 입력하지 않는 것이 필요한 경우가 있다.
이 경우에는 다음과 같이 insert ignore 문을 활용하여 중복된 키를 가지면 입력을 시키지 않도록 할 수 있다.
아래 예제는 unique 키가 두개의 키값에 걸려있는 경우 첫번째 id 값이 입력되지 않아도 insert 문이 동작하기에 다음과 같은 예제를 사용한다.
아래의 경우 가령 james라는 키값과 barkely라는 키값에 unique 키가 걸려있고 해당 데이터가 이미 존재하는 경우 아래의 insert 문은 그냥 무시된다.
example1
2ALTER TABLE person ADD UNIQUE INDEX (first_name, last_name)
INSERT IGNORE INTO person VALUES (NULL, 15, 'James', 'Barkely')
nodejs 페이스북 회원가입
개요
클라이언트에서 웹페이지의 버튼 클릭 등으로 이미 구축해 놓은 server의 url에 페이스북 토큰과 함께 로그인 요청을 보내면, 서버는 passport 모듈을 통해 받은 토큰을 facebook에 보내어 인증을 거치고 페이스북에서 거친 인증값을 담아 서버의 callback 라우터에 요청을 보낸다.
서버는 요청을 받고 accessToken을 저장하며 accessToken과 유저정보들을 jwt 암호화를 거쳐 jwt를 발급하여 클라이언트에게 다시 보내어 준다.
클라이언트는 받은 jwt를 localStorage에 저장하고 앞으로 자동 로그인시에 해당 jwt 토큰을 사용한다.
passport 설치
1 | npm install --save passport |
모듈 import 하기
1 | var NaverStrategy = require('passport-naver').Strategy; |
필요한 모듈을 import 해준다.
개발자 정보를 비롯한 기밀 정보들 별도 파일에 저장
1 | module.exports = { |
federation 객체에 네이버, 카카오, 페이스북 Developers 정보를 입력한다.
secret.js 민감한 정보를 갖고있는 파일들은 프로젝트 디렉토리에 포함시키지 않는 것이 바람직하다.
서버코드 작성
1 | var secret_config = require('../commons/secret'); |
passport.use를 통해 OAuth 요청을 만들어서 네이버 로그인 처리를 진행하고 요청결과를 callback url로 라우팅 시켜줌을 설정한다.
먼저 auth/login/facebook으로 요청이 오면 페이스북으로 로그인 요청을 보내고 결과값을 callback url로 보내준다.
callback url을 처리하는 라우터는 로그인이 성공할 경우 인덱스 페이지로 리다이렉트 시켜주고 실패할 경우에는 다시 로그인 페이지로 리다이렉트 시켜준다.
앵귤러의 경우 특정 페이지에 리다이렉트 되면 컴포넌트가 생성되는 시점에서 query의 뒷부분에 붙은 email 과 jwt를 가지고 jwt는 저장하고 email로 유저의 정보를 받아와 클라이언트에서 사용한다.
/auth/facebook/callback은 페이스북이 검증을 마치고 난 결과를 전송해주는 주소이다.
서버의 로그인 함수 작성
1 | function loginByThirdparty(info, done) { |
auth.id 기반으로 신규 회원인지 기존 회원인지 판단한다.
신규 회원일 경우에는 user 테이블에 회원 정보를 저장 시키고 로그인 처리를 진행하고, 기존 유저일 경우에는 쿼리로 조회한 회원정보를 기반으로 로그인 처리를 진행합니다.
간단하게 말씀드리면 신규회원이든 기존 회원이든 원클릭으로 회원 가입 절차를 진행하게 할 수 있습니다.
스타트업 초기 마케팅
스타트업 초기 마케팅
서비스 초기의 스타트업에게 가장 어려운 부분 중 하나는 바로 효과적인 마케팅을 하는 것이다.
최근의 마케팅 트렌드는 SNS를 활용한 컨텐츠 유포를 통한 바이럴 마케팅 인데, 충분하지 못한 자금과 인력을 가진 스타트업에게는 이러한 콘텐츠 하나를 제작하는 것 마저 큰 부담이 된다.
이렇듯 충분치 못한 자금과 인력으로도 운영 가능한 훌륭한 여러가지 마케팅 방법들을 소개한다.
1. 블로그 마케팅
블로그를 활용한 마케팅은 이미 활성화되어 있는 플랫폼의 블로그 기능을 이용하여 사용자들의 유입을 도모하는 것이다.
이러한 블로그 마케팅을 해 나감에 있어 핵심적인 요소는 바로 훌륭한 컨텐츠의 생산이다.
아무리 블로그 운영에 비용이 들지 않는다고 하더라고 훌륭한 컨텐츠가 제작되지 않는다면 유입률이 보장되지 않으며, 블로그의 경우 사람들이 쉽게 구독을 하지 않으므로 오히려 SNS 채널에 비해 손도 많이가고 지속적인 유입도 확보하기 힘들다.
대부분의 블로그 방문의 경우 유입 경로는 검색포털에서의 검색으로 사람들이 많이 검색을 하는 키워드가 포함된 글의 경우 유입이 높을 수 있다.
판매하는 제품이 온라인에서 많이 검색되는 키워드인 경우 이러한 블로그 마케팅이 효과를 볼 수 있다.
검색을 통한 유입을 위해 반드시 핫한 키워드를 텍스트에 담는 것 이 매우 중요하다.
블로그의 경우 네이버, 다음 등에서 상위 5개 노출이 핵심이며 그 외의 글들을 사실상 노출되지 않기 때문에 블로그를 활용한 마케팅을 위해서는 지속적으로 포스트를 하며 상위 노출을 시켜야 한다.
이처럼 블로그는 검색을 기반으로 하여 유입이 이루어 지기 때문에 최대한 핫한 키워드를 잘 캐치하여 이를 제목 및 본문에 잘 녹여내어야 높은 노출효과를 볼 수 있다.
많은 스타트업들의 경우 자신들의 제품을 알리기 위해 정말 제품과 서비스에 대한 상세한 정보를 담으려고 노력하지만 이런식의 포스팅은 검색량이 매우 적기 때문에 높은 노출효과를 보기는 어렵다.
즉, 블로그 마케팅의 핵심은 검색량이 많은 주요 키워드를 잘 선정하는 것이다.
이를 위해 네이버 광고, M-자비스 등의 서비스를 이용하여 광고 키워드를 선별한 뒤에 검색하여 나온 컨텐츠를 면밀히 살펴본 뒤 사람들이 흥미를 느끼는 핵심 키워드를 찾아 정리한 뒤에 이 키워드를 기반으로 포스팅을 하면 높은 노출효과를 얻을 수 있다.
2. 커뮤니티를 통한 마케팅
판매하는 제품과 관련이 있는 커뮤니티 그룹에 홍보 글을 올리는 것이다.
블로그와 마찬가지로 돈이 들지 않고 일정 정도 이상의 유입이 반드시 보장되지만, 계속 홍보성 글을 올리는 경우 커뮤니티 원들 사이에 좋지 않은 이미지가 확산 될 수 있고, 장기적으로 보면 브랜드 이미지를 해칠 수 있기 때문에 해당 커뮤니티의 분위기에 맞게 간접적으로 홍보할 수 있는 글을 지속적으로 올리는 것이 바람직하다.
커뮤니티 목록
클리앙
SLR 클럽
루리웹
뽐뿌
네이트판
디시인사이드
리뷰리퍼블릭
머신러닝강의 5강 - 머신러닝 테스트 및 정확도 향상의 방법론
머신러닝의 정확도
머신러닝에서의 정확도는 다양한 변인들에 의하여 판가름 난다.
그 중 제일 큰 부분을 차지하는 변수는 바로 learning rate, data preprocessing, overfitting 이며 본 강의에서는 각 요소들이 어떻게 영향을 미치고 정확도를 개선 할 방법에 대해 알아본다.
적당한 learning rate의 선택
learning rate는 gradient descent algorithm을 사용할 때에 학습이 진행됨에 따라 학습의 속도 혹은 변화도를 통제하는 변수이다.
만약 learning rate이 너무 크다면 최저점을 찾을 때 1회 이동의 정도가 너무 크기 때문에 발산할 가능성 즉 overshooting의 위험이 있으며, 너무 작으면 속도가 매우 느린 단점이 있다.
정확도 향상을 위한 data preprocessing
만약 입력받은 두 종류의 변수의 크기 차이가 심한 경우 이는 학습에 큰 영향을 미칠 수 있기 때문에 학습 전에 data preprocessing을 거쳐 정확도를 높일 수 있으며, 흔히 normalize라고 불리는 정규화 작업을 거친 뒤 학습을 하게 된다. 이러한 standardize를 위한 수식은 다음과 같다.

overfitting
overfitting이란 학습된 결과가 학습을 위한 데이터에 너무 맞추어져 있는 것을 의미한다.
이는 주로 적은 수의 학습데이터가 주어져 있을 경우 발생하기 쉬운데, 넓은 범위의 학습데이터가 아니기 때문에 해당 학습데이터에 치우친 결과값이 나와 정확도가 떨어지는 측면이 있다.
이러한 overfitting을 해결하기 위해서는 먼저 충분한 양의 학습데이터를 확보를 하고, 학습하는 feature의 수를 줄이는 것, 또 regularization을 하는 것이 도움이 된다.
1. mongodb 시작하기
Installation
installation on ubuntu
먼저 다음과 같이 mongodb가 설치되어 있는지 확인한다.
mongod는 서버, mongo는 클라이언트 이다.
1 | mongod --version |
만약 설치가 되어있지 않다면 다음 명령어로 설치를 진행한다.1
2
3
4
5sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 2930ADAE8CAF5059EE73BB4B58712A2291FA4AD5
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu precise/mongodb-org/3.6 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.6.list
sudo apt-get update
sudo apt-get install -y mongodb-org
설치가 완료되었다면 아래의 명령어로 서비스를 실행시킨다.1
sudo service mongod start
서비스가 정상적으로 실행되었는지 확인하기 위해 다음과 같은 명령어를 사용한다.1
sudo service mongodb status
이제 다음 명령어로 mongodb에 접속한다.1
mongo
접속이 완료되었다면 database를 관리하기 위한 계정을 만들어야 한다.
이 계정을 통해 외부 컴퓨터에서도 본 database에 접근할 수 있게 된다.
다음과 같은 admin database에 접근하여 root user를 생성한다.1
2use admin
db.createUser({user: "root", pwd: "mypassword", roles: [{ role: "root", db: "admin" }] });
유저를 생성하였다면 다음 명령어로 설정파일을 열어 authorization을 enabled로 해준다.1
cd /etc/mongod.conf
설정이 완료되었다면 mongodb를 다시 실행시킨다.1
sudo service mongod restart
다시 시작한 뒤에는 사용할 계정을 만들어 준다.1
2
3
4
5use app #app 대신에 내가 만들 db명을 선택
db.createUser(
{ user: "app",
pwd: "mypassword",
roles: ['readWrite','userAdmin'] } )
생성한 아이디로 로그인 해본다.1
mongo -uapp -pmypassword app
connect to mongodb
1 | mongo --port <포트> -u "<사용자 계정>" -p "<비밀번호>" --authenticationDatabase "admin" |
Configuration
보안설정 바꾸기
Vim /etc/mongod.conf
Basic Concepts
Collection
create collection
1 | db.createCollection(name, [options]) |
delete collection
1 | db.COLLECTION_NAME.drop() |
Schema
일종의 데이터의 양식이다.
이 스키마를 기반으로 모델을 생성한다.
Model
일종의 커넥션으로 다른 것들은 이 모델 객체에서 바로 수행한다.
여기서 새로운 데이터를 저장하는 save를 하기 위해서는 instance를 생성하여야 하고,
다른 경우는 이 모델에서 바로 수행한다.
Query
update
example
1 | db.getCollection('schedule').update({"email":"test"}, {$set:{"email":"test@test.com"}}, {muti:true}); |
Transaction
서버버전 4 이상에서 제공한다.
featurecompatibility를 “4.0” 으로 해야한다.
commitTransaction()은 sessionEnd 까지 포함된 개념이다.
Uninstallation
1 | sudo service mongod stop |
Cookbook
위치 찾기
1 | db.collection.createIndex( { <location field> : "2dsphere" } ) |
npm 시작하기
npm 시작하기
package.json 의 항목들 최신버전으로 업데이트하기
1 | npm i -g npm-check-updates |
Building a node.js app with typescript
개요
In this post, you will learn how to deploy a node.js server in a typescript environment.
기본적인 서버 및 데이터베이스의 구축에서 부터 실제 배포 및 개발환경 세팅에 이르는 실제 운영을 위한 여러 고려사항들을 검토하고 논의하며 ubuntu 운영체제를 기본 환경으로 사용한다.
Installation
At first, install node.js web server
먼저 홈페이지에 들어가서 노드js를 설치한다.
nodejs 홈페이지
nodejs를 설치했다면 apt-get의 로컬 패키지를 업데이트 해준다.1
sudo apt-get update
리눅스계열 os의 경우 다음 code로 설치한다.
npm의 경우 원래는 nodejs 안에 포함되어 같이 깔리지만 커맨드가 안잡힌다면 아래 별도 명령어를 통해 다시 설치해 준다.
1 | sudo apt-get install -y nodejs |
cmd에서 node –version으로 설치가 잘 되었는지 확인하고 npm을 통해 다양한 모듈을 세팅한다.
만약 aws 서버의 경우 보안 문제 때문에 제대로 설치가 되지 않을 수 있다.
그럴때는 –unsafe-perm 을 붙여 설치를 진행해 본다.
대부분의 문제가 해결될 것이다.
npm의 버전이 맞지 않아 패키지 설치에 문제가 있는 경우 npm을 최신버전으로 업데이트 해야 한다.
하지만, npm을 업데이트 하기 전에 그에 상응하는 최신 nodejs를 설치해 주기 위해 nodejs 버전관리 모듈인 n을 설치해 주고 새로운 nodejs를 설치해 준다.1
2sudo npm install n -g
sudo n stable
설치가 완료된 뒤에 다음 명령어를 입력하여 제대로 버전이 바뀌었는지를 확인한다.1
node -v
여기서 버전이 제대로 업데이트 되지 않았다면 다음과 같이 수동으로 입력해 준다.1
sudo ln -sf /usr/local/n/versions/node/6.0.0/bin/node /usr/bin/node
npm을 최신으로 업데이트 해 준다.1
sudo npm install npm@latest -g
shell을 재실행 시킨 뒤 npm의 버전이 변경되었는지 확인한다.1
npm -v
Compile Typescript
typescript 컴파일러인 tsc 를 통해 다음과 같이 컴파일 할 수 있다.
1 | tsc |
typescript compile 할 때에 필요한 다양한 옵션을 tsconfig.json 파일에 명실 할 수 있다. 필자의 경우는 file import 시에 다음과 같이 alias 를 사용하였기 때문에 해당 alias 의 위치를 tsc 가 찾을 수 있도록 tsconfig.json 에 paths를 등록해 준다.
1 | { |
이처럼 path의 경우 단지 컴파일러에게 해당 파일이 어디에 있는지에 대한 위치정보만을 가르쳐줄 뿐이며, 이는 컴파일되어도 alias의 값이 그대로 들어가게 된다.
이러한 module-alias 를 실행하기 위해서는 다음과 같이 module-alias 를 설치하고 메인 파일에서 이를 등록해 주어야 한다.
1 | npm install --save module-alias |
index.ts
1 | require('module-alias/register'); |
이러한 alias의 위치를 실행시점에서 지정해 주어야 하며, 그는 package.json 파일에 다음과 같이 지정해 주어야 node 엔진이 해당 파일을 찾아서 실행이 가능하다.
package.json
1 | { |
Paths 뿐만 아니라 컴파일 시에 타겟 언어를 지정하고, 모듈관리, 소스맵 등의 다양한 옵션을 설정해 준다.
How to manage environment variables
서버를 운용함에 있어 개발 환경과 실제 운영서버에 따라 달라지는 다양한 환경변수들을 관리하는 것은 보안 및 시스템의 관리 측면에서 매우 중요하다.
본 프로젝트에서는 docker container 기술을 사용하여 운영서버를 배포하며, 개발 서버의 경우 로컬 머신을 사용한다.
여기서 운영서버의 경우 docker image 를 생성하는 시점에서 사용되는 Dockerfile 에 운영시에 사용되는 environment variable 을 저장
서버를 여러 배포환경에서 배포하기 위해 dotenv 라이브러리를 사용하여 .env 파일 내의 환경 변수를 프로세스 환경변수로 사용할 수 있다.
여기서 만약 .env 파일 내의 변수가 기존의 환경 변수와 충돌이 난다면 .env 파일에서 설정한 변수는 무시된다.
머신러닝강의 4강 - multinomial classification
multinomial classification이란?
저번 포스트에서는 logistic classification 중에서 binary classification에 대해서만 다루었으나, 오늘은 보다 많은 변수값을 기준으로 보다 많은 종류의 결과값들 중에서 선택을 하는 알고리즘인 multinomial classification에 대해 학습한다.
가령 학생들의 시험성적의 경우 각 과목의 점수를 종합하여 전체 평점이 A~D 사이로 결정이 되는데, 이러한 복수의 결과값 중 하나를 선택하는 학습 알고리즘이다.
다음 그림은 각 결과값을 위한 다양한 Weight 값을 종합으로 판단을 하는 것을 그림을 통해 보여주고 있다.
각 결과값이 true이냐 혹은 false이냐를 결정짓는 Weight를 종합하여 hypothesis function을 만들어 낼 수 있다.
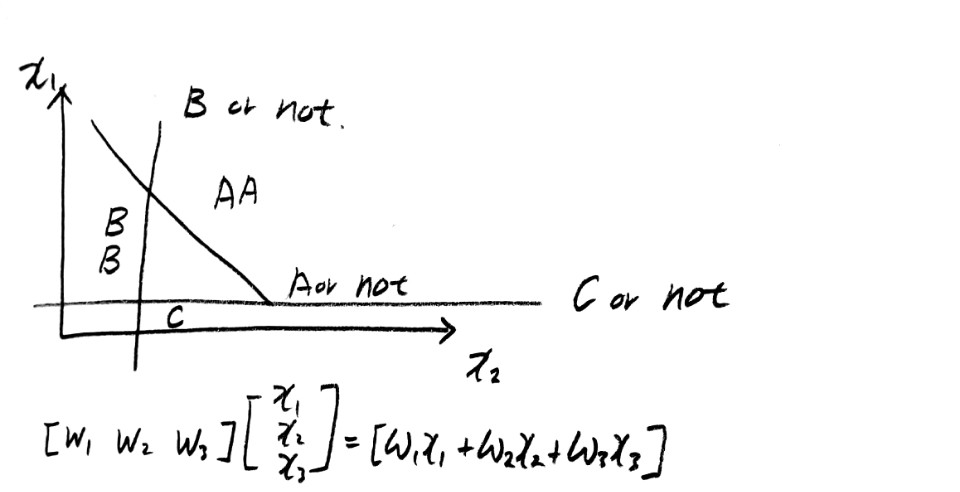
위 내용을 식과 다이어그램으로 표현하면 다음과 같다.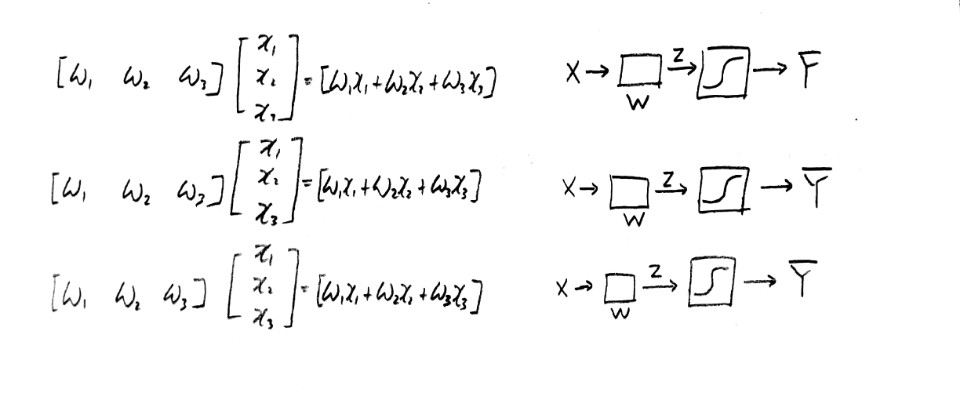
이는 matrix를 이용하여 간략하게 표현될 수 있다.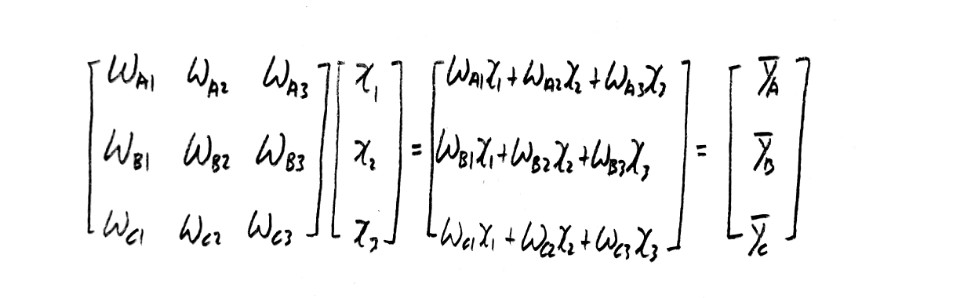
위와 같이 결과값의 예측값을 구하면 그 범위는 0에서 1사이의 구간이 아니라 많은 편차를 나타내게 된다.
하지만, multinomial classification에서의 최대 관심사는 특정 입력값이 들어갔을 때에 결과적은 어떤 결과값이 선택되는 가에 대한 것이기 때문에, 특정 결과값이 나올 확률에 대한 궁금증을 가지기 시작했고 softmax 를 통해 결과값을 확률값으로 변환시켰다.
softmax 함수와 그 방식은 다음과 같다.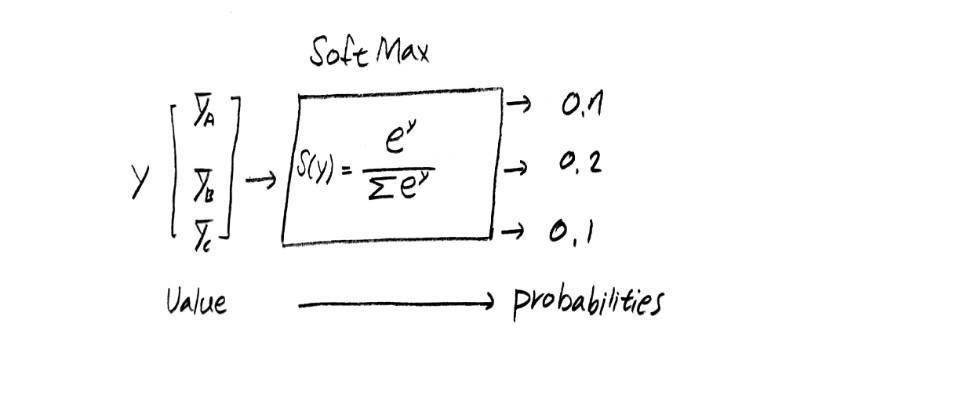
multinomial classification에서의 cost function / cross entry cost function
위와 같은 softmax 함수를 통해 나온 값의 cost function을 구해 이를 최소화 시키는 gradient descent 알고리즘을 적용시키기 위해서 정확한 cost function을 구해야 할 필요가 생기게 되었고, 그 식은 일명 cross entry cost function이라 불리는 다음의 식을 따른다.
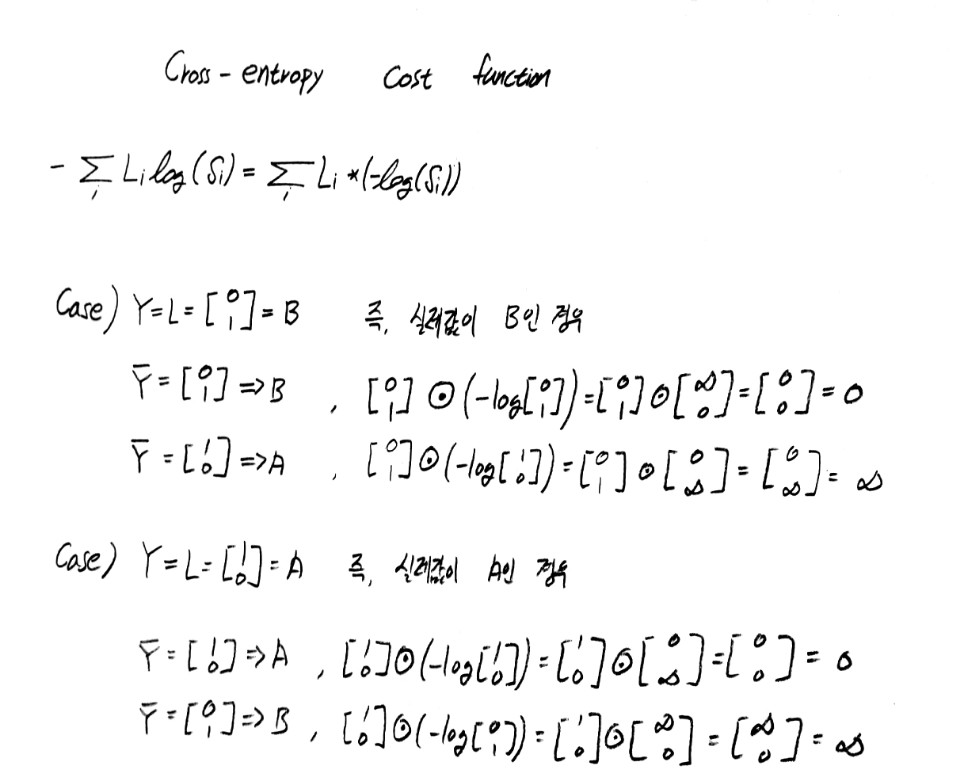
위 사례를 통해 위 식은 cost function가 충족해야 할 조건인 참인 경우 0 참이 아닌경우 무한대라는 조건을 훌륭하게 만족시키며, 비록 형태는 다르지만 binary classification에서의 cost function과 비교해 볼 때 특정 결과값의 요소만 반영하는 방식에 있어서 결국은 같은 형태의 식이다.